ما هو SkillOpt؟ طريقة Microsoft لتطوير وكلاء الذكاء الاصطناعي دون تعديل النموذج
يقدّم SkillOpt من Microsoft طريقة جديدة لتطوير وكلاء الذكاء الاصطناعي تقوم على تدريب «المهارة» — أي ملف تعليمات مكتوب بلغة طبيعية — بدلًا من تدريب النموذج نفسه، فلا حاجة إلى تعديل أوزانه أو تحمّل تكاليف الـ Fine-tuning.
لم يعد الذكاء الاصطناعي مجرّد أداة تُجيب عن الأسئلة. لقد تحوّل إلى وكيل ذكي قادر على استخدام الأدوات، وقراءة الملفات، وتنفيذ الأوامر، والبحث عن المعلومات، وحلّ المسائل المعقّدة.
لكن نجاح هذا الوكيل لا يعتمد على قوة النموذج وحدها، بل على طريقة تصرّفه: كيف يجمع الأدلة؟ كيف يستخدم الأدوات؟ كيف يتحقّق من النتيجة؟ وكيف يصوغ إجابته النهائية؟
هنا تظهر فكرة المهارة (Skill)، أي مجموعة تعليمات مكتوبة بلغة طبيعية تساعد الوكيل على أداء مهمة بطريقة أفضل. ومن هذه الفكرة وُلد مشروع SkillOpt.
ما هو SkillOpt؟
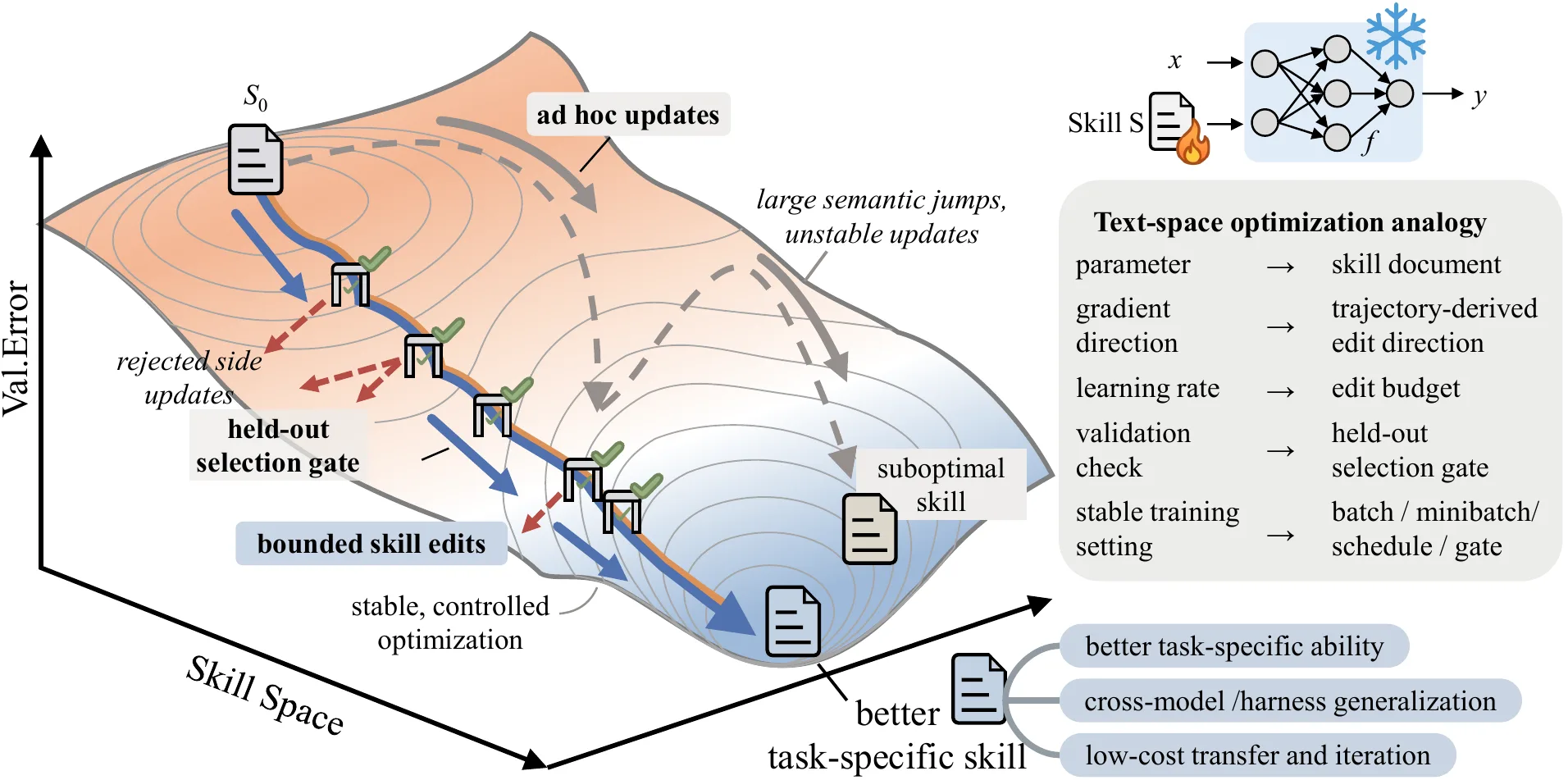
SkillOpt مشروع من Microsoft يقدّم طريقة لتدريب «مهارة» مكتوبة بلغة طبيعية، بدلًا من تدريب النموذج نفسه.
بمعنى آخر، لا يعدّل SkillOpt أوزان النموذج، ولا يحتاج إلى Fine-tuning تقليدي. بل يحسّن ملفًّا نصيًّا صغيرًا يحتوي على قواعد وإرشادات تساعد النموذج على أداء مهامه بكفاءة أعلى.
تخيّل SkillOpt كأنه مدرّب يراقب أداء الوكيل عبر مجموعة مهام، يرصد الأخطاء والنجاحات، ثم يحدّث كتيّب التعليمات الخاص بالوكيل. وبعد عدة جولات، يَخرج بملف نهائي مثل best_skill.md يحمل أفضل مهارة تعلّمها النظام.
لماذا نحتاج إلى SkillOpt؟
تحسين أداء وكلاء الذكاء الاصطناعي ليس سهلًا دائمًا. فالطرق التقليدية، مثل كتابة الأوامر (Prompts) يدويًّا أو تعديل التعليمات بعد كل خطأ، كثيرًا ما تكون غير مستقرّة.
أحيانًا تُضيف قاعدة جديدة فتحلّ مشكلة وتخلق أخرى. وأحيانًا تصبح التعليمات طويلة أو متضاربة. يعالج SkillOpt هذه الفوضى عبر عملية منظّمة تشبه التدريب:
- تنفيذ المهام.
- مراقبة النتائج.
- تحليل الأخطاء والنجاحات.
- تعديل المهارة.
- اختبار التعديل.
- قبول التعديل فقط إذا حسّن الأداء.
بهذه الطريقة، يصبح تحسين التعليمات أكثر دقة وانضباطًا، وأقلّ اعتمادًا على التجربة العشوائية.
الفكرة الأساسية: المهارة كملف قابل للتدريب
في SkillOpt، يبقى النموذج ثابتًا، والذي يتغيّر هو ملف المهارة. ويحتوي هذا الملف على تعليمات تحدّد:
- متى يستخدم الوكيل أداة معيّنة.
- كيف يتحقّق من صحة الإجابة.
- كيف يتعامل مع الأخطاء.
- كيف ينظّم خطوات التفكير والتنفيذ.
- كيف يصوغ النتيجة النهائية.
تتحسّن المهارة تدريجيًّا بينما يظلّ النموذج كما هو. وهذه نقطة بالغة الأهمية، لأن كثيرًا من النماذج مغلقة أو مكلفة عند إعادة التدريب. فبدل إعادة تدريب النموذج، نُحسِّن طريقة استخدامه.
كيف يعمل SkillOpt خطوة بخطوة؟
1. البداية بمهارة أولية
تنطلق العملية من ملف مهارة بسيط يحمل تعليمات عامة، مثل: اقرأ السؤال جيدًا، واستخدم الأدوات عند الحاجة، وتحقّق من النتيجة قبل الإجابة، واكتبها بوضوح. هذه ليست المهارة النهائية، بل نقطة الانطلاق.
2. تنفيذ المهام (Rollout)
يستخدم النموذج المهارة لتنفيذ مجموعة من المهام، فيما يُعرف بمرحلة Rollout. وخلالها يُسجَّل كل ما يحدث: الرسائل، واستخدام الأدوات، وخطوات الحل، والمخرجات، والأخطاء، ودرجة النجاح أو الفشل. الهدف هو فهم كيف يتصرّف الوكيل فعليًّا عند تطبيق المهارة.
3. تحليل النجاح والفشل (Reflection)
في مرحلة Reflection، يقرأ نموذجٌ آخر يُسمّى نموذج المحسّن (Optimizer Model) النتائجَ ويحلّلها. ولا يكتفي برصد خطأ واحد، بل يبحث عن أنماط متكرّرة: هل ينسى الوكيل التحقّق من إجابته؟ هل يختار الأداة الخطأ؟ هل يتسرّع قبل جمع معلومات كافية؟ وهل ينجح دائمًا حين يتّبع خطوة معيّنة؟ هكذا يتعلّم SkillOpt من الأخطاء والنجاحات معًا.
4. تعديل المهارة
بناءً على التحليل، يقترح النظام تعديلات على ملف المهارة: إضافة قاعدة جديدة، أو حذف قاعدة غير مفيدة، أو توضيح خطوة غامضة، أو منع سلوك يسبّب الأخطاء.
لكن SkillOpt لا يسمح بتغيير كل شيء دفعة واحدة. فالتعديلات محدودة عمدًا، حفاظًا على ما كان يعمل جيدًا في المهارة السابقة. ويشبه ذلك «معدّل التعلّم» في تدريب النماذج، لكنه هنا يجري على مستوى النص والتعليمات.
5. اختبار التعديل (Gate)
لا يُقبل أي تعديل مباشرة، بل يُختبر أولًا على مجموعة تحقّق منفصلة في مرحلة Gate.
إن تحسّن الأداء، قُبِلت المهارة الجديدة. وإن لم يتحسّن، رُفض التعديل. وهذا ما يمنح SkillOpt موثوقية تفوق التعديل اليدوي العشوائي.
ماذا يحدث للتعديلات المرفوضة؟
لا تضيع التعديلات المرفوضة. إذ يحتفظ بها SkillOpt كإشارة سلبية تذكّره أن هذا النوع من التغييرات لم يكن مفيدًا، فيتجنّب تكراره في الجولات التالية.
ما الفرق بين SkillOpt وهندسة الأوامر (Prompt Engineering) التقليدية؟
تعتمد هندسة الأوامر التقليدية على كتابة تعليمات جيدة يدويًّا ثم تعديلها بالتجربة، أما SkillOpt فيحوّل هذه العملية إلى تدريب منظّم وقابل للقياس. ويتّضح الفرق بينهما في خمسة جوانب رئيسية.
فالطريقة التقليدية يدوية في الغالب، في حين يعمل SkillOpt بشكل شبه تلقائي. وهي تعتمد على التجربة وحدها، بينما يقوم SkillOpt على دورة من التنفيذ والتحليل والاختبار. كما أنها قد تكون غير مستقرّة، أما SkillOpt فأكثر تنظيمًا. ومن حيث التعديلات، قد تكون عشوائية في الطريقة التقليدية، في حين لا يَقبل SkillOpt أي تعديل قبل اختباره. وأخيرًا، يصعب في الطريقة التقليدية معرفة سبب التحسّن، بينما يتيح SkillOpt تتبّع التعديلات والنتائج بوضوح.
فهو لا يكتب أمرًا واحدًا فحسب، بل يطوّر مهارة كاملة بطريقة قابلة للقياس.
النتائج التي أعلنها المشروع
وفق صفحة المشروع والورقة البحثية، اختُبِر SkillOpt على معايير ونماذج وبيئات تنفيذ متعدّدة، وحقّق تحسينات واضحة مقارنةً بعدم استخدام مهارة. ومن الأمثلة المذكورة: تحسين أداء نماذج GPT و Qwen، وتحسين نتائج مهام البحث والأسئلة، والتعامل مع الجداول، وفهم المستندات، وحلّ المسائل الرياضية، وأداء الوكلاء في البيئات التفاعلية.
كما يشير المشروع إلى أن المهارة الناتجة يمكن استخدامها في بيئات مختلفة، مثل المحادثة المباشرة و Codex و Claude Code. وهذا يعني أن تطوير المهارة النصية قد يُحدث أثرًا كبيرًا دون تعديل النموذج نفسه.
هل يمكن نقل المهارة من نموذج إلى آخر؟
نعم، وهي من أبرز نقاط قوة SkillOpt. فبعض المهارات المحسّنة قابلة للنقل من نموذج إلى آخر، أو من بيئة إلى بيئة قريبة منها. يمكن مثلًا تدريب مهارة في بيئة معيّنة ثم إعادة استخدامها في بيئة مشابهة.
هذا يجعل المهارة الناتجة أصلًا قابلًا لإعادة الاستخدام؛ فبدل البدء من الصفر في كل مرة، نستخدم مهارة مدرّبة مسبقًا ونعدّلها عند الحاجة.
لماذا يهمّ هذا الشركات والمطوّرين؟
يقدّم SkillOpt طريقة عملية لتحسين وكلاء الذكاء الاصطناعي دون تكاليف الـ Fine-tuning الباهظة. وبالنسبة إلى الشركات، يعني ذلك تحسين الأداء دون تعديل النموذج، وخفض تكلفة التدريب، وإمكانية مراجعة التعليمات يدويًّا، وسهولة نقل المهارة بين المشاريع المتقاربة، وتقليل الأخطاء المتكرّرة عبر تحسين قابل للاختبار.
أما المطوّرون فيجدون فيه طريقة أفضل لبناء وكلاء يعتمدون على أدوات وملفات وبيئات تنفيذ معقّدة.
أبرز حالات استخدام SkillOpt
- البحث والإجابة عن الأسئلة: تعليم الوكيل كيف يبحث، ويتحقّق من المصادر، ويكتب إجابة دقيقة.
- التعامل مع المستندات: توجيهه إلى قراءة المستندات بعناية واستخراج المعلومات المهمة دون اختلاق ما ليس موجودًا.
- الجداول والبيانات: مساعدته على فهم الجداول وتوليد الكود المناسب والتحقّق من النتائج الحسابية.
- البرمجة: تحسين طريقته في قراءة الكود وفهم الأخطاء واقتراح حلول وتنفيذ تعديلات منظّمة.
- البيئات التفاعلية: تدريبه على اتخاذ قرارات أفضل ضمن مهام متعدّدة الخطوات.
حدود SkillOpt
رغم قوّته، ليس SkillOpt حلًّا سحريًّا لكل شيء، وله حدود ينبغي مراعاتها:
يحتاج إلى تقييم واضح. يعمل بأفضل صورة حين تتوفّر طريقة محدّدة لقياس النجاح، مثل اختبار ينجح أو يفشل، أو درجة دقة، أو ناتج قابل للتحقّق. أما المهام المفتوحة جدًّا أو المعتمدة على رأي بشري فيصعب تقييمها.
يحتاج إلى تكلفة أثناء التدريب. فرغم صِغر المهارة النهائية، يتطلّب تدريبها تنفيذ عدة مهام واستخدام نموذج محسّن. لذا قد لا يناسب مهمة صغيرة تُستخدم مرة واحدة، لكنه مجدٍ جدًّا عند الاستخدام المتكرّر.
لا يعوّض ضعف النموذج الأساسي. فهو يحسّن طريقة استخدام النموذج، لكنه لا يحوّل نموذجًا ضعيفًا إلى قوي. وإن كان النموذج لا يفهم المجال أساسًا، فستكون فائدة المهارة محدودة.
أسئلة شائعة عن SkillOpt
هل يعدّل SkillOpt النموذج نفسه؟ لا. يحسّن SkillOpt ملف المهارة النصي فقط، بينما تبقى أوزان النموذج ثابتة دون أي Fine-tuning.
ما الفرق بينه وبين هندسة الأوامر؟ هندسة الأوامر غالبًا يدوية وتجريبية، بينما يطوّر SkillOpt المهارة عبر دورة منظّمة من التنفيذ والتحليل والاختبار، ولا يقبل أي تعديل قبل إثبات أنه يحسّن الأداء.
هل المهارة الناتجة قابلة لإعادة الاستخدام؟ نعم، إذ يمكن نقل كثير من المهارات المحسّنة إلى نماذج أو بيئات قريبة، ما يجعلها أصلًا يُعاد استخدامه بدل البدء من الصفر.
متى لا يكون SkillOpt الخيار الأمثل؟ عندما يصعب قياس النجاح بموضوعية، أو عند تنفيذ مهمة صغيرة لمرة واحدة لا تستحقّ تكلفة التدريب.
الخلاصة
يقدّم SkillOpt تحوّلًا في طريقة تطوير وكلاء الذكاء الاصطناعي: فبدل الاستثمار في إعادة تدريب مكلفة، نُدرّب طريقة العمل عبر مهارة نصية قابلة للقياس وإعادة الاستخدام. والنتيجة أداء أفضل، وتكلفة أقل، وشفافية أعلى في فهم سبب التحسّن.
إن كنت تبني وكلاء ذكاء اصطناعي أو تسعى إلى رفع كفاءتهم دون أعباء الـ Fine-tuning، فابدأ بتجربة منهج المهارات على إحدى مهامّك الأكثر تكرارًا، وقِس الفرق بنفسك.
المصادر
مقالات ذات صلة

روبن هود تطلق التداول الآلي بالذكاء الاصطناعي: الوكلاء يحصلون على محافظ مالية حقيقية
أطلقت منصة التداول الشهيرة روبن هود (Robinhood) ميزة التداول الآلي المدعوم بالذكاء الاصطناعي، مما يسمح للوكلاء الذكيين بإدارة المحافظ المالية وتنفيذ الصفقات بشكل مستقل لملايين المستخدمين. تمثل هذه الخطوة سابقة في قطاع الخدمات المالية الاستهلاكية، حيث تمنح وكلاء الذكاء الاصطناعي صلاحيات مالية حقيقية.